Pushing DNS into the Cloud

For the majority of the past five years, Pushover has run on one physical OpenBSD server. It does have a hot spare hosted with another company in another part of the country, but usually everything has been served from just one machine at a time. Its MariaDB database is replicated in a master-master configuration over a secure tunnel between the servers so that either node can become active at any time.
When I wanted to take the primary server down for upgrades or the server's
network provider was having routing troubles, I would update DNS for various
pushover.net entries to point at the other server's IPs where all of the
components were already running.
Within seconds, traffic would start hitting the secondary server and within a half
hour, everyone would be using it, allowing me to take the primary server offline
as long as I needed.
Table of Contents
As Pushover's traffic grew, I wanted to distribute the load between both nodes. If both servers were in the same datacenter, the natural solution would be to put a load balancing server in front of them that proxied requests to a random node behind it. The load balancer would do its own health checks and quickly stop sending requests to a failed node.
Since Pushover's nodes were in different parts of the country on different networks for redundancy, putting a load balancer in front of them would add a lot of latency and itself become a single point of failure for the two nodes.
However, load balancing through DNS is pretty easy and remains distributed.
Each pushover.net DNS entry got multiple IPs and my DNS servers replied to each
query with both records in random order.
The traffic was distributed between both nodes surprisingly equally, and life was
good.
That is, until SQL replication broke.
SQL Key Conflicts
For particular API calls such as registering new users and devices, data from the user has to be unique. Only one user record can have the same e-mail address, only one device can have the same OS-provided push notification token. These requirements are enforced by ActiveRecord validations on the API side, and backed by SQL unique index constraints underneath.
While the API was being served by both servers at once, occasionally I would see the
same API request hit both at nearly the same time.
Despite being the same API request, each server has even or odd auto-incrementing
IDs (configured in my.cnf), and randomly generated secrets and timestamps are
different for the same request.
This causes the same request to write two different SQL rows when handled on two
different nodes (or the same node when run twice).
On the first server, ActiveRecord would check SQL, not find a row, write a new one, and then MariaDB would send that row to the other server for replication. When the second server got the same API request quick enough and the timing worked out such that the new row was written to SQL on the second node before the replicated row from the first server reached it, MariaDB would try to apply the replicated row with conflicting data and stop replication until manual intervention (i.e., deleting one of the two rows).
I never figured out what conditions caused clients to send the same request to both IPs at once, but it was not something I could guarantee against because it's an open API. At this point, I had to go back to having a primary server with just a hot spare.
Selective Distribution
The most common API call for Pushover is
/1/messages
which queues new notifications, and since it doesn't have the same problem of both
nodes possibly writing conflicting data, being able to distribute its load would be
quite beneficial.
I thought of a few different strategies for solving this, such as:
-
Making my Android and iOS apps, which have to use the possibly-conflicting API endpoints for creating new users and devices, use a different DNS name for talking to the API which would only ever point to one node while the rest of the world would still use
api.pushover.netpointing to both. -
Introducing some kind of out-of-band locking for the possibly-conflicting API calls. Before checking SQL for an existing user record when creating a new one, a lock would be established on the other server to block it from servicing any API calls for the conflicting data such as the user's e-mail address.
-
Making ActiveRecord on the secondary server talk directly to SQL on the primary server (over its already-established secure tunnel) just for these possibly-conflicting API calls.
-
Making Rails on the secondary server proxy the HTTP request to the primary server just for these particular API calls.
Eventually I decided on the last one since it looked to be the least invasive, least error-prone, and most able to be rescued in case of a temporary communication problem between the two nodes.
Using the
rails-reverse-proxy
gem, I created a method called as a before_filter on just the eleven low-traffic
API methods that needed this protection.
When running on the secondary server, Rails will proxy these requests to the primary
and if a valid response is received, it will stop further processing and send the
proxied result to the client.
If the proxy request takes more than a few seconds or gets a 500 error, the
before_filter falls through and Rails handles the request locally.
I submitted a
pull request
for rails-reverse-proxy to add an on_connect callback so I could fine-tune the
error handling.
If the secondary node successfully connects to the primary server (including
TLS negotiation), this callback fires and sets a flag.
During the timeout handling, if that flag is set, the request is not handled
locally and a 500 error is sent to the client.
Without it, there's no way to know whether the timeout happened during the
connection (ok to fallback), during request transmission (maybe ok to fallback),
or while waiting for the response (not ok to fallback).
It's better to serve the occasional 500 error and let the client retry than to
handle the request twice and possibly hit the same SQL conflict.
Failing Over
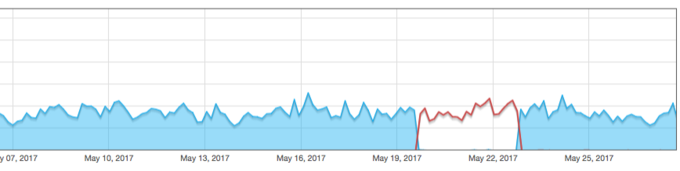
With the proxying solution in place, I was able to go back to DNS responding with both IPs and distributing the load between the two servers. This has been in place for about a month and I've been quite happy with it.
One day when I got an alert that one of the two Pushover servers was unreachable from my network monitor (which turned out to be a problem with the network monitor), I thought about how best to handle the situation of needing to take a node out of DNS.
I could have created some mechanism so my network monitor could trigger a change on my three DNS servers, but it seemed like a lot of work. My DNS changes are otherwise done by hand, editing zone files and pushing them to a Git repo which the three servers read from and reload.
While doing some performance testing recently, I noticed that a non-trivial source of latency in accessing Pushover's API was the DNS lookup stage. My three DNS servers are all in the US and are not exactly optimized for extremely low latency (they are run-of-the-mill servers doing various things in addition to DNS).
In addition to having an established, monitored global network of low-latency anycasted DNS servers, most major DNS providers offer some concept of health checking and automated record changes. The provider's network of servers around the world will ping (through ICMP or HTTP) one's servers every minute or so and when errors are detected, an action is triggered that does something to one's hosted DNS records. This is either taking the faulty node's records out of DNS or switching to alternate records that point to a backup datacenter.
After recognizing these two needs, I realized this was not something I wanted to
setup and maintain myself, so I started looking at using a 3rd-party DNS provider
for the pushover.net domain.
NS1
I started with NS1 which had reasonable pricing at $25/month.
This package included two "monitors" which I configured to be HTTP probes pointing
to a private API endpoint on each of the Pushover servers.
Their web dashboard has some pretty graphs showing per-record query statistics.
After signing up and configuring a test pushover.net zone in their dashboard, I
ran into a severe limitation.
NS1's offering only includes one "filter chain", which is the action that happens
when one of the two included monitors reports an error.
Since there are many different records in pushover.net that need to get modified
when a node is taken down such as client.pushover.net, api.pushover.net,
www.pushover.net, pushover.net's MX records, etc., and many of them have IPv4
and IPv6 which means separate A and AAAA records for each of those, I would have
needed at least ten "filter chains".
Even using some clever CNAMEing to only have to rewrite one set of records would
still have required two filter chains, one for A and one for AAAA.
I contacted NS1's support about this to make sure I was understanding how filter chains worked, and whether I actually needed ten of them. I got this reply the next day:
Apologies for the delayed reply as we do not receive alerts when tickets are submitted by free-tier customers. Your understanding of Filter Chains is correct, you will need a Filter Chain for each DNS record that requires some form of answer load balancing. If you require ~10 Filter Chains, our business development team can help find a more appropriate plan. We customize packages to meet your needs in our Enterprise packages
I was not a free-tier customer, I was paying $25/month. I was also a bit surprised that there was no web interface for creating support tickets (and thus, authentication), you just e-mail support@ns1.com. I waited a couple days and never heard back from their "business development team", so I canceled the account (again through an unauthenticated e-mail).
I later found the plan customization tool on their signup page (which is not on their dashboard allowing plan changes after signing up) and saw that ten "filter chains" would cost $700/month.
DNS Made Easy
Up next was DNS Made Easy, which had a "business" package for only $4.99/month. This plan included "3 failover records", but additional ones were only $4.95/year.
While configuring my zone through their site, I discovered that their health checks
had to be performed on the record being manipulated.
This meant that to remove an IPv4 and IPv6 address from www.pushover.net (A and
AAAA records), their system had to be doing an HTTP check on both the IPv4 and
IPv6 IP, against both nodes.
Multiplied by all of the IPs and records I needed to manipulate, this would actually
be double the ten health checks I needed with NS1, and that would be twenty HTTP
pings hitting my API from multiple DNS Made Easy servers, all the time.
A minor nit: DNS Made Easy's website didn't allow importing a BIND-style zone for faster configuration, like NS1 did.
Dyn, Cloudflare
I looked at a few other DNS providers that I could find, but I wasn't satisfied with their offerings enough to signup. Dyn's website didn't even give pricing information and required calling into their sales team (what year is it?) and Cloudflare's website didn't make it clear whether I would be able to do monitoring and record modification with just their DNS service (as opposed to buying their full suite of CDN proxying stuff).
Amazon Route 53
I'm somewhat skeptical of AWS because they've had more global downtime than Pushover has had with one guy maintaining two pokey servers over the past five years. Since DNS is stateless, I'll give Amazon the benefit of the doubt that they're better able to route around failure with their Route 53 DNS service than they are at moving stateful hypervisors and virtual machines.
The pricing for Route 53 was quite cheap, costing $0.50/month for the zone, $0.40/month for the traffic up to a million queries, and $0.75/month for the health checks. The nickel-and-diming of AWS gets a tad annoying with $1.00/month surcharges for each "additional feature" such as HTTPS and "string matching".
I signed up for Route 53 and right away, the process becomes a bit daunting. The AWS control panel presents one with dozens and dozens of service offerings, each one encouraging the reading of lots of documentation and whitepapers. It has a Google feel to it, constantly getting pushed to their user forums for help rather than contacting a human.
Even though I started with Route 53, each time I had to configure something like the alert notifications or look at logs, I'm bounced around to some other AWS service because each one operates somewhat independently (SNS for notifications, CloudWatch for logs).
Eventually I got everything configured and after some testing, made the leap to
point pushover.net's nameservers to Route 53's.
I re-ran the previous performance tests and they showed a noticeable improvement in
the DNS lookup stage, especially from non-US locations.
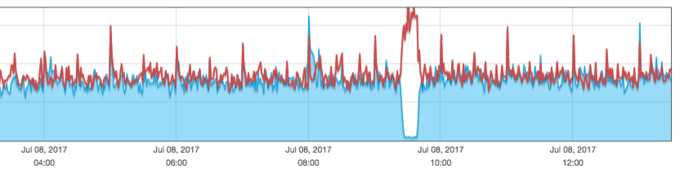
Now the removal of a failed node is completely automated so I don't have to worry about always being around to manually edit DNS records. I did a test yesterday to make one of the nodes return a 500 status for the endpoint that AWS checks and within about a minute, the DNS records were updated and all traffic was flowing to a single node, then back to both a short while later: